声明:本站所有资源均来自网络,版权归原公司及个人所有。如有版权问题,请来信告知,我们将在第一时间予以删除,谢谢!
联系邮箱:pwshangwuduijie@gmail.com
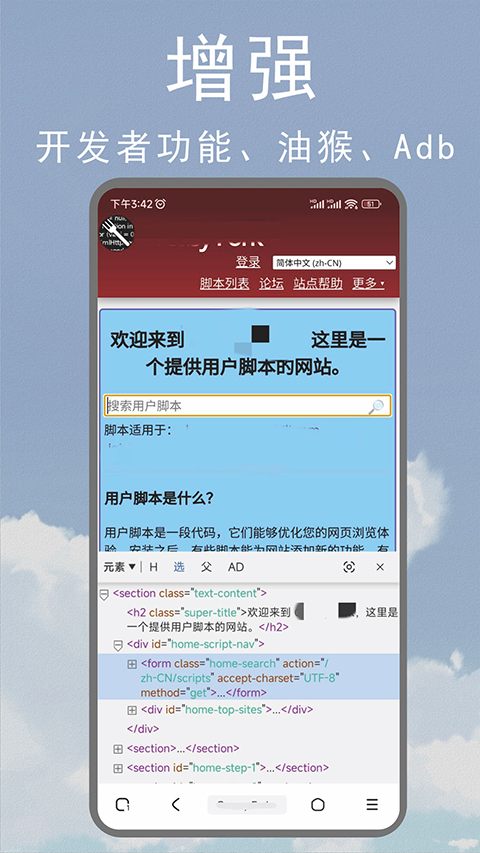
这是一款在手机上使用的浏览器工具软件,它非常好用,不受任何限制,能打开各种网站。软件的整体界面设计得十分简洁,还能为用户智能拦截网页中的弹窗广告和垃圾信息。此外,它具备智能检索和超级聚合搜索功能,可以全方位满足用户查找所需信息的需求,确实非常实用。同时,它还支持插入各种脚本工具进行使用。有需要的用户,欢迎在本站下载使用。
首先需要明确的是,轻站并非网站,它本质上是一个简化版的小程序框架,其视图由安卓底层直接渲染,而非借助WebView(浏览框)实现,所以轻站和网站实际上没有关联。
目前轻站的设计更适配后端开发者开展API调试工作。后续的设计规划中,轻站将朝着原型设计的方向发力,助力产品或原型岗位人员在交付给客户端开发工程师前,完成原型交互功能的确认,从而降低因UI或参数调整引发的客户端代码重构频次。毕竟我本身也是开发人员,深知修改和调试代码往往比编写代码更耗费时间。
另一方面,轻站框架作为一款面向极客的工具,同样具备数据整合能力,能够实现更高效的数据预览效果。但请务必注意,切勿利用这一特性从事任何非法活动! 考虑到小团队的交流需求,轻站框架的功能设计允许通过扩展方式进行导出使用。为防止有人利用其可输出的特性进行非法买卖,软件不提供加密功能,也无法实现加密(通过口令导出时显示的乱码仅为压缩后的结果,并非真正的加密处理),还望理解!
轻站本身不提供任何数据内容,也不对内容进行检验和限制,所以在使用其功能的过程中,所有风险需由您自行承担,若不愿承担风险,则请不要使用该功能。
创建一个新轻站或编辑已有引擎

轻站框架组成
轻站由属性、模块、接口、常量、资源这五个板块构成,其中模块是核心部分。
属性,轻站的信息。
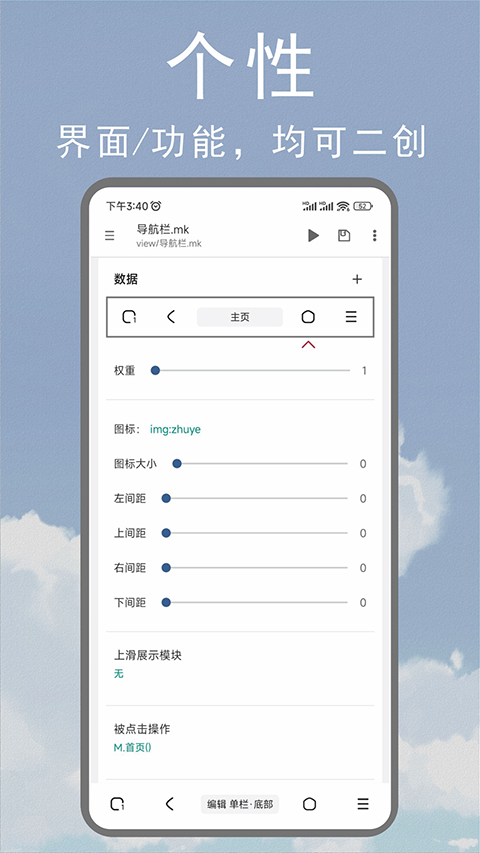
模块等同于页面,一个页面既可以只包含单个模块,也能由多个模块相互嵌套构成。举例来说,一个常规的列表只需采用一个列表模块就行;要是你打算在列表顶部嵌入一个幻灯片,那就得另外添加一个幻灯片模块,再把列表嵌套进去。若想通过嵌套更多模块让界面更丰富,就需要用到面板模块,它能够同时嵌套N个不同类型的模块,从而实现多样的视觉效果。
接口是软件打开轻站的一个入口,首页指的是在轻站列表中点开后默认加载的页面,搜索页面则是搜索该轻站时所展示的页面。
常量,指的是固定不变的数值,在模块运行过程中,需通过获取变量的方式来对其进行获取。
资源,用于存放JS文件、图片文件等本地资源,供模块调用,不过该功能目前暂未开放,因此暂不做介绍。
模块详解
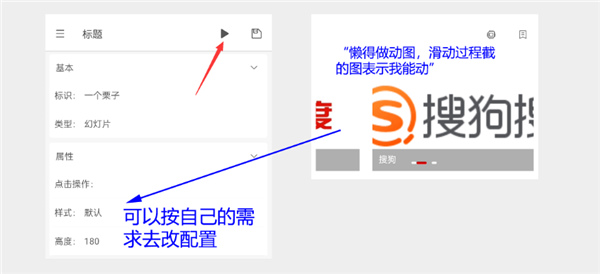
理论终究不如实践来得实在,就拿幻灯片模块来说,如图所示:如果是还没接触过轻站的新手同学,一定要新建一个窗口来创建轻站,再按照图中的步骤完成操作。跟着一步步做下来,基本就能掌握轻站的制作方法了!
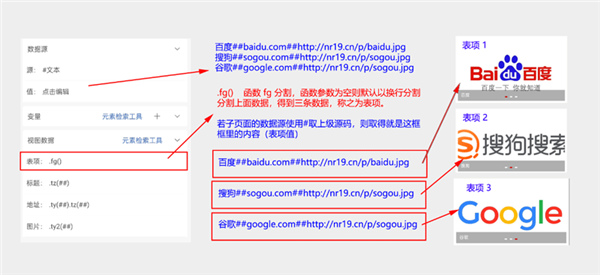
数据源值:
百度##baidu.com##http://nr19.cn/p/baidu.jpg
搜狗##sogou.com##http://nr19.cn/p/sogou.jpg
谷歌##google.com##http://nr19.cn/p/sogou.jpg
视图数据值:(长按检索工具可一键导入)
表项=.fg
标题=.tz(##)
地址=.ty(##)。tz(##)
图片=.ty2(##)
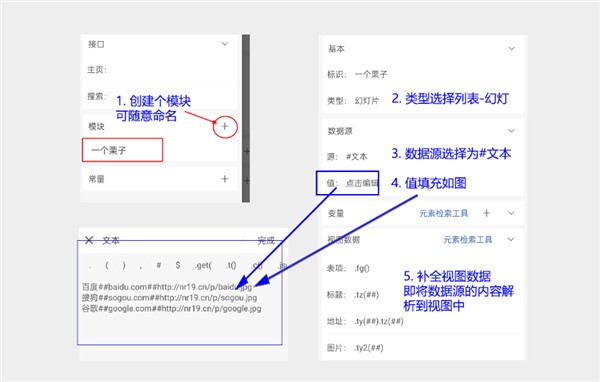
完成上面步奏,一个页面就做好咯,系部系很简单的啦
数据源指的是视图的源内容,既可以通过#爬虫获取网络或本地的文本内容,像API、网页这类都可以;也能和上面的例子一样,直接用#文本放置一段固定的文本内容。嗯,先来看一下轻站的运行流程图:
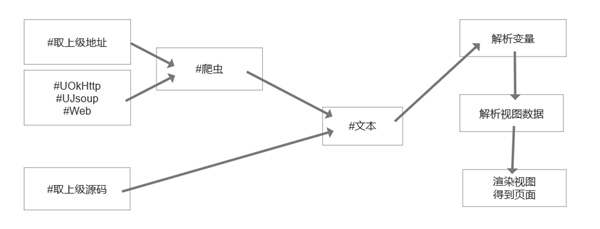
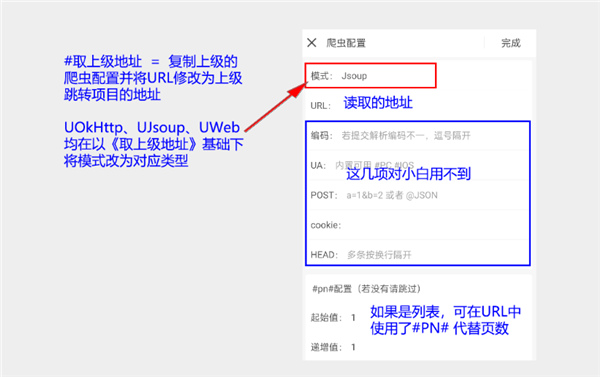
如上图所示,不管你对数据源进行何种类型的操作,最终目的都是获取一段文本,然后交给页面渲染器解析并渲染出界面。对了,数据源里的#爬虫标签,其实和真正的爬虫关系不大,但也并非毫无关联。 爬虫的配置图解:
解析器采用了E2表达式——这是为开发本软件专门原创的新功能,若想了解具体的解析函数,可参考文章《E2表达式函数大全》。依据上述运行流程图,系统会优先解析“变量”数据;实际上视图数据本身就属于变量范畴,只是自定义变量会被优先处理。在E2表达式中,变量的调用是被允许的,模块里设置变量的目的,主要是避免视图数据单行E2无法完成细致解析的情况,不过通常来说,自定义变量的使用并非必需。
到这里,轻站功能的开发就介绍完了,相信你也已经掌握了轻站的原理,是不是特别简单。
要打开在本站的M浏览器,首先需进入软件首页,接着点击轻站按钮。
第二步,点击右上角的+号。
第三步,点击源仓库。
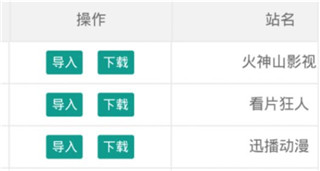
进入下面这个界面后,大家就能挑选自己需要的源了,找到合适的,点击导入就行哦。
E2表达式应用在M浏览器的爬虫功能中,要是你打算自行尝试编写脚本,就需要对它有所了解。
E2 表达式
用于处理文本的表达式,例如要获取“文本”前面的几个字,就可以用.tz(文本)这个方式得到“用于处理”这四个字。E2函数名采用中文拼音首字母来命名,这样即使是不懂开发的人也能轻松上手操作。
E2 具备数组操作功能,M浏览器中轻站或虫子获取列表的函数就需要用到数组。为了让大家更轻松地理解和使用这些函数,通常处理文本的函数都以“t”开头——比如取文本左边的函数是tz,这里t代表文本,z是“左”的拼音首字母,由此也能推知取文本右边的函数是ty。而处理数组的函数则以“i”开头,像.ij(aaa)这个函数,j表示“加”,作用是往数组里添加一行,其值为aaa。
以下函数仅支持 2.3.5 及以上版本支持
文本操作类:
.tz .ty 取文本左、右数据。
.tz2 与 .ty2 的功能是从后向前读取判断值文本,并提取该判断值左侧(前面)和右侧(后面)的数据。当文本内容为 abbacc 时,调用 .ty(a) 会得到结果 bbacc,而调用 .ty2(a) 会得到结果 cc。
.t 删除HTML标识,无需提供参数,如内容为
a
b
提取正文时若要去除html代码,直接使用.t就行,最终结果会是ab。
.tj 添加内容,比如若已有 ab,想得到 abcd 的话:.tj(cd)
.tzc 参数需为数字形式,例如写成 tzc(5)。当当前操作值的字数超过该数字时,就截取前对应数字的字数;若字数不足,则保留全部内容。因此这里的 zc 代表可截取的最大长度。假设操作值是 ABCDE,使用 .tzc(3)的话,得到的结果是 ABC。
.tsk 命令没有参数,功能是去除首尾的空格;qswk 再加上 t 的话名称太长不便于记忆,所以就保留首空的设定,实际意思和去首尾空是一样的,也就是对操作对象的开头和结尾的空格字符进行移除处理。
.th 用于替换操作,参数格式为“欲替换文本##替换文本”。例如,当内容是 ABC 且要把 B 改成 2 时,可使用 .th(B##2);若想将 B 置空,直接用 .th(B)即可得到 AB。此外,th 中的欲替换文本支持正则表达式,若替换内容与正则通配符冲突,需进行转义。像处理 111ADGDGS333 这类相对复杂的内容,要把中间的英文字母替换为 333,可使用 .th([A-Z]+##333)。要是不清楚哪些是正则匹配符,建议使用 .th2,它与 th 唯一的区别是欲替换文本不支持正则匹配。
.tx x 所代表的含义是“新”,而这个“新”的概念在下方的数组中也有对应的函数。M浏览器扩展在使用E2的时候,都必须先对源内容进行定义,就像数据源爬虫对应的是读取到的网络内容,文本对应的是已定义好的文本那样。这里我们假定源内容为xByyEzz,需要获取的是E后面的值以及B前面的值(需要注意的是,其中的内容x、y、z是会动态变化的),重点是要获取E后面且B前面的部分。新的概念指的是,把之前操作得到的值存储起来且保持不变,让后续操作的函数处理的对象是源内容本身。要是能理解这句话,应该就清楚该如何操作了,具体分三个步骤:第一步,获取E后面的值,即ty2(E);第二步,进行存储操作,并将当前操作的内容定义为源内容tx;第三步,获取B前面的值,即.tz(B)。
快速梳理一下,源内容xByyEzz在调用E2时会自动转换为操作值,随后执行ty2(E),取E后面的部分就把操作值设置成zz,接着通过.tx存储当前操作值并将操作值重置为源文本xByyEzz,再运行tz(B)得到x。之后没有其他函数了,就把之前存储的值和当前操作值一起输出,最终结果是xyyzz。
加解密操作:
.en 加密 .dn 解密
.en(base64) / .dn(base64)----- base64 加密与解密
.en(md5) --- 获取MD5
.en/dn(utf-8、gbk等编码类型)——URL编码与解码
aes、des、3des加解密,注意参数之间以小写逗号分隔,输出类型仅支持两种:hex(16进制)和base64
.en/dn(aes、模式、密码、编码、输出类型、偏移量)
数组操作类:
.i(正数)用于获取数组中的指定内容,索引从0开始计数。例如,获取第一个值用.i(0),获取第三个值用.i(2),以此类推。
.i(负数索引)是从数组的尾部开始进行查找的,其中-1对应的就是数组的倒数第一个元素,-2对应的是数组的倒数第二个元素,后续的负数索引以此类推。
.i(数值1,数值2)用于获取数组的指定范围,这里需要理解正数和负数参数的不同用法——参数既可以填正数,也可以填负数,具体选择哪种更便于判断就用哪种。举个例子,若有数组 [ab,ac,ad,ae],想要得到 ac、ad、ae(也就是排除第一个元素),可以写成 .i(1,-1);要是想排除最后一个元素,得到 ab、ac、ad,就写成 .i(0,-2)。
.ij(添加的文本) 将"添加的文本"添加到数组里,例如数组原本是 [aa,bb,cc],执行操作后就变成 [aa,bb,cc,添加的文本]
.ix 用于存储数组,之后和 tx 的处理方式相似,把操作值替换为原始文本。需要注意的是,在进行数组操作时要接着执行其他函数。
.it(分割符)在E2中,i代表数组,t代表文本。要把数组合并成文本,并且在数组元素中间用参数里的分隔符来填充;要是没有填入参数的话,就不需要添加分隔符
正则表达式
.z参数中若包含括号,需添加转义才能被E2识别;要是正则表达式里的括号较多,在E2中查看会显得繁杂,此时可以在参数前后添加两个@来标识参数内容。例如正则表达式为(a(b)c)|(x(y)z),其作用是匹配a(b)c或者x(y)z,在E2里必须给括号再添加一个转义符,写成.z((a(b)c)|(x(y)z))的话看起来会很混乱,而如果在参数两侧加上双@,写成.z(@@(a(b)c)|(x(y)z)@@),视觉上就会相对清晰整洁一些。
.z2 用于匹配子表达式,其编写方式与前述相同,这里的子表达式指的是正则表达式内部的对应内容,匹配完成后可通过 .i 来获取指定括号中的内容。若想了解正则语法,可点击此处查看:https://www.runoob.com/regexp/regexp-syntax.html
CSS选择器
.css(选择器语法)会返回匹配结果的数组,关于匹配语法的详细说明可参考链接:https://blog.csdn.net/weixin_34375233/article/details/89656172
.a(属性名)用于获取对应属性的值,比如获取a标签的跳转地址href属性时,可写成.a(href);获取img标签的图片地址src属性时,可写成.a(src)。
XML解析器
.xml(标签名) 和 .css 用法一致
JSON解析器
.json(参数名)无论是普通对象还是数组对象,都使用这个命令。数组对象会返回数组,文本对象会返回文本(也可以把它看作只有一个子项的数组)。
超级聚合搜索,整合多引擎与多爬虫,支持灵活自定义,是极客不可或缺的实用功能
直接在中且零基础就能开发的轻站小程序功能
支持m3u8视频
支持审查元素功能且能够随意修改网页内容
支持悬浮播放器 + 长按倍速功能
支持DLNA电视投屏功能
支持长按快速搜索,选中文字翻译、全局翻译
支持强大的ADB广告过滤插件
支持兼容油猴脚本功能
支持把第三方工具,像IDM、ADM这类设置成默认浏览器
支持多内核浏览器切换
创新的隐藏手势操作,大屏时代,单手依然操作自如
v3.2.4.0706版本
更新说明:
修复通用设置项视频长按倍速设置无效
修复部分机型扫码报错
书签列表增加方块显示选项